State of the Art Models — Feb 5, 2026
Same-day releases: Claude Opus 4.6 (Anthropic) vs GPT-5.3-Codex (OpenAI).
TL;DR
Opus 4.6 goes wide: massive context, enterprise workflows, PowerPoint, knowledge work. GPT-5.3-Codex goes deep: best-in-class coding benchmarks, self-improvement, mid-task steering.
Claude Opus 4.6
- 1M token context window
- Enterprise/knowledge work focus
- 500+ zero-days found (security research)
- Agent Teams in Claude Code
- 4 effort levels (adaptive thinking)
- PowerPoint integration
GPT-5.3-Codex
- Wins coding benchmarks (SWE-Bench Pro, Terminal-Bench 2.0, OSWorld)
- Faster inference
- Mid-task steering
- Self-improvement (helped build itself)
- Codex parallel agents
- ~400K context window
Self-Reported Benchmarks
Take vendor-reported benchmarks with a grain of salt — always validate with real-world usage.
Benchmarks
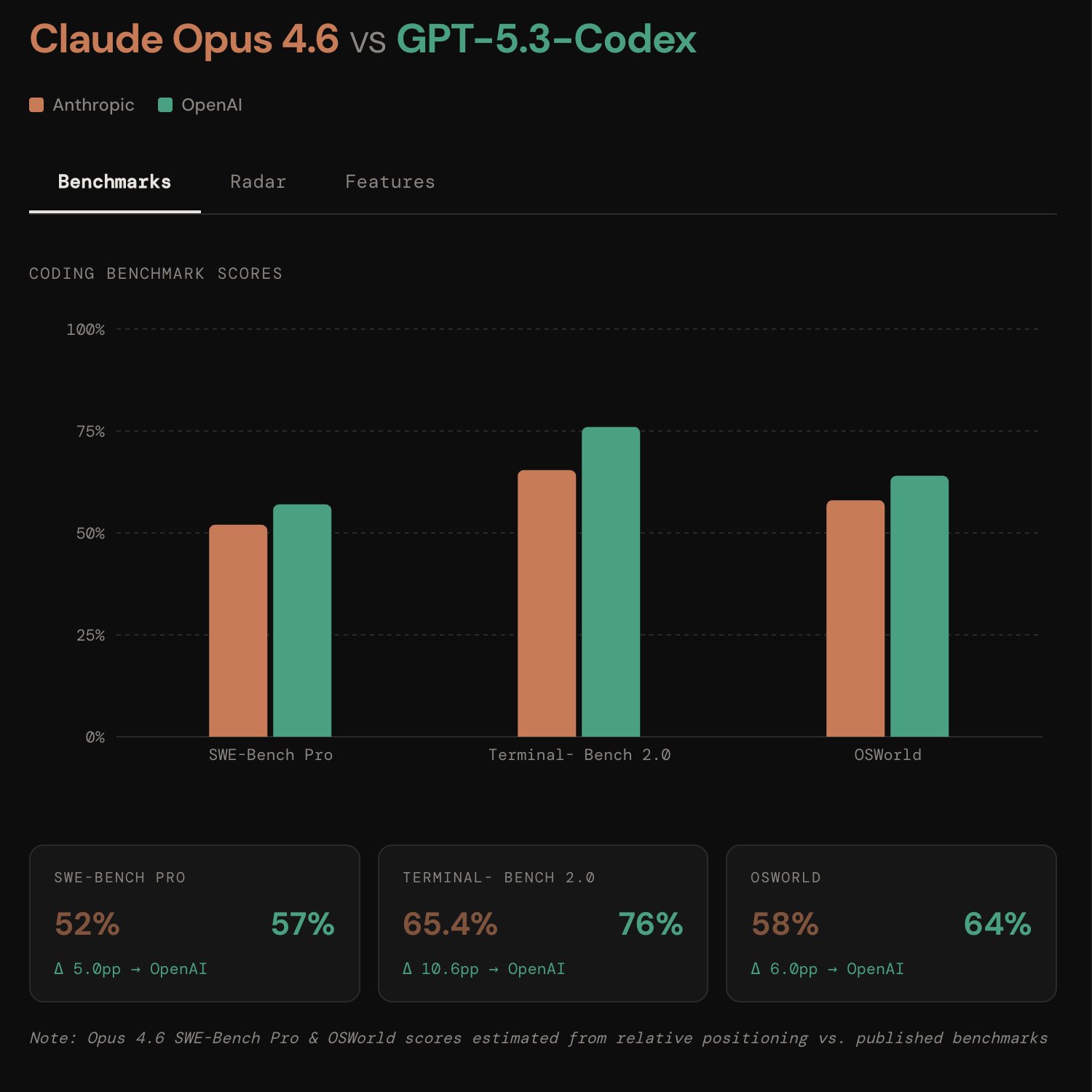
| Benchmark | Opus 4.6 | GPT-5.3-Codex | Delta |
|---|---|---|---|
| SWE-Bench Pro | 52% | 57% | +5.0pp → OpenAI |
| Terminal-Bench 2.0 | 65.4% | 76% | +10.6pp → OpenAI |
| OSWorld | 58% | 64% | +6.0pp → OpenAI |
Capability Radar
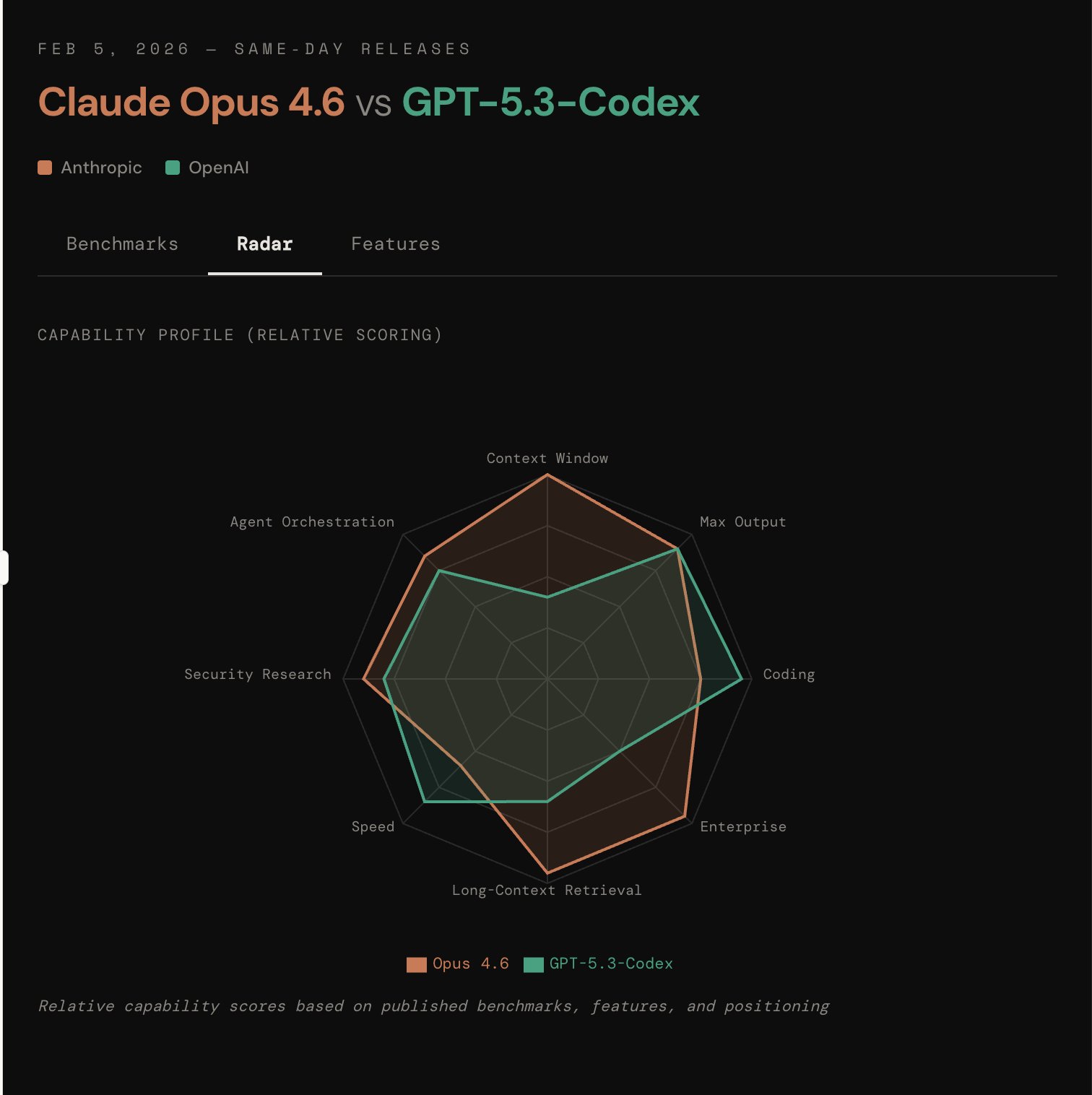
Feature Comparison
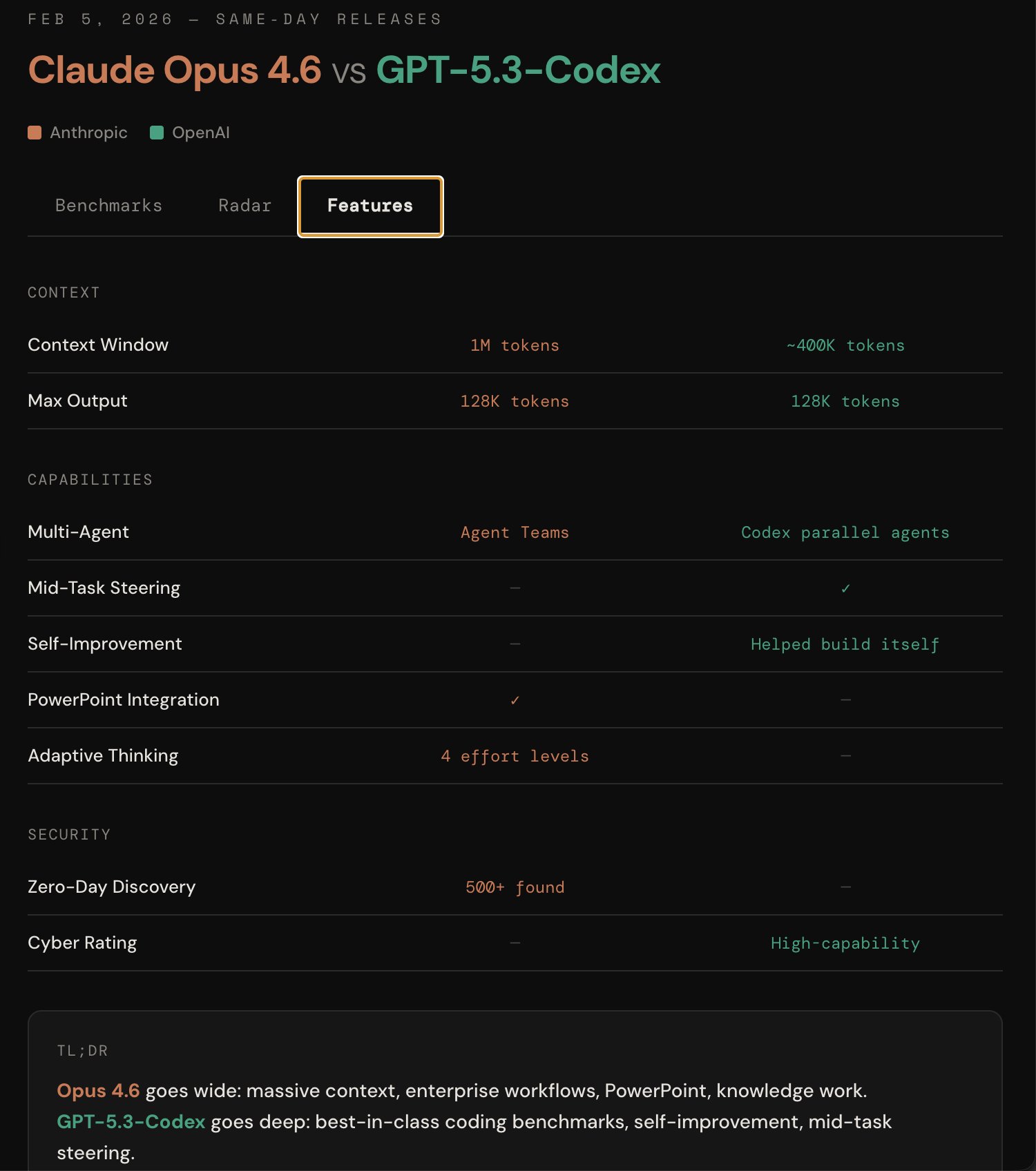
| Category | Opus 4.6 | GPT-5.3-Codex |
|---|---|---|
| Context Window | 1M tokens | ~400K tokens |
| Max Output | 128K tokens | 128K tokens |
| Multi-Agent | Agent Teams | Codex parallel agents |
| Mid-Task Steering | — | ✓ |
| Self-Improvement | — | Helped build itself |
| PowerPoint Integration | ✓ | — |
| Adaptive Thinking | 4 effort levels | — |
| Zero-Day Discovery | 500+ found | — |
| Cyber Rating | — | High-capability |